
Coding Standards: How we at Bitfactory produce qualitative, well formatted and clean code
21. Juni 2021
11 Minuten zum lesen
11 Min.
Office Stuttgart
Bitfactory Solutions GmbH
Gutenbergstr. 77a
70197 Stuttgart
Germany

21. Juni 2021
11 Minuten zum lesen
11 Min.

21. Juni 2021
8 Minuten zum lesen
8 Min.
Werden Sie Teil unserer Mailing Liste und bleiben Sie informiert über Tech, Apps, Backend
Recently I needed to choose a framework for On-Device text recognition (also called OCR - Optical Character Recognition) for an iOS project. After some research it turns out that both big players Apple and Google offer solutions for On-Device-OCR: With iOS 11 Apple released the Apple Vision framework. On the other side Google offers the MLKit text recognition framework as a part of their MLKit suite. First off, what actually is On-Device OCR?
OCR means Optical Character Recognition. In simple terms an input image with text in it is processed by an OCR framework which outputs the detected text. This is usually performed by some machine learning models. Since both frameworks from Apple and Google are closed source and we only work with the frameworks programming APIs we can image the internals of the OCR frameworks as a machine learning blackbox 🙂
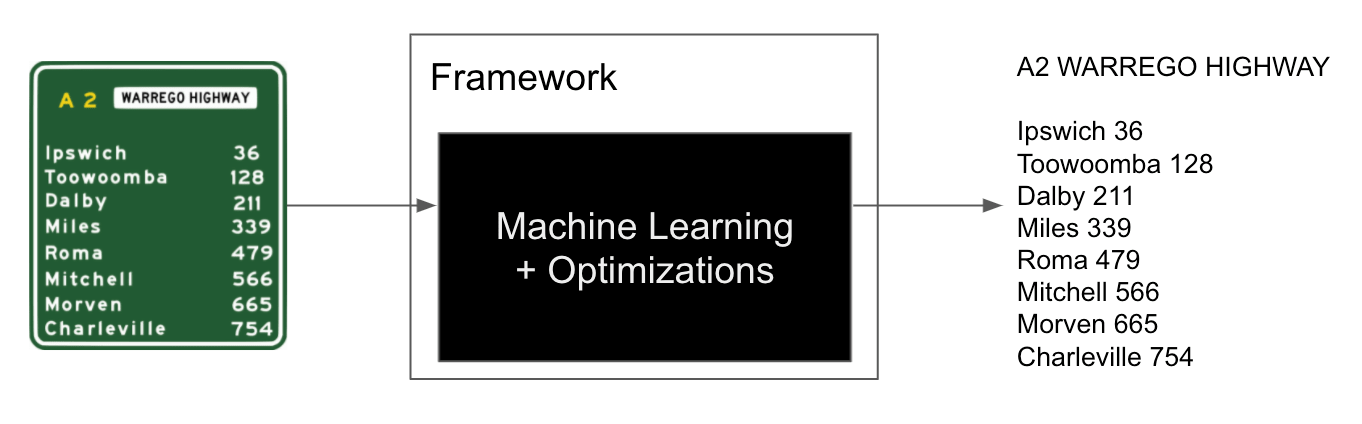
The On-device part simply means that the recognition is performed on the device’s processor without any network connection to external servers. Since mobile processors became pretty powerful today, they are capable of handling the recognition in a reasonable amount of time.
After some more digging around I found this awesome blog post by Omar M’Haimdat which already compares both frameworks. Although his post already gives an idea about the differences, I wanted to verify it by myself and check out if things had changed since 2019. (Version 1.3.0 was used for MLKit text recognition framework)
First let’s talk about the obvious differences between Apple’s Vision Framework and Google’s MLKit Text framework:
Apple Vision is exclusively available in Apple’s ecosystem. If you want to deploy to both iOS and Android and have the same OCR results you have to stick to MLKit which is available for both Android and iOS. Another important difference are the supported languages. Google’s MLKit text recognition is only capable of detecting characters from the latin script. On top of that Apple’s Vision API offers a detection for simplified chinese. (6/2021)
All the presented results are based on my personal test sets and do not have any scientific base. Furthermore I only tested with a few devices. Different test sets with different devices might lead to different results.
Both API’s enable you to get the positions of the detected text in boxes. This can be pretty handy if you need to scan for example documents which always have the same structure. I created a demo app which continuously renders the detected rectangles as blue boxes on the screen, which looks like this:

Google’s MLKit API is pretty plain and simple. Beside that, you can get an array of detected languages in those boxes and that’s it. Apple Vision’s API on the other lets you choose between a ‘fast’ and an ‘accurate’ mode. When using the fast mode, the results for the recognized text were pretty underwhelming. So I continued comparing the accurate mode with MLKit. Furthermore Apple’s API shows the confidence values (from 0 to 1) from the machine learning model for the detected text results. That sounds neat but was pretty useless in my use cases, since you usually go with the best match and the other results don’t offer any additional value. Other than that you can specify custom words in Apple’s Vision API which can be useful in some scenarios if you have special words which you are looking for. Apple advertises with a ‘language correction’ phase ‘to minimize the potential for misreadings’ (Apple). During my testing I could not determine that this phase offers an actual benefit to the plain recognition from MLKit.
To sum this section up: Apple clearly wins in terms of marketing and advertising their framework to programmers but at least in my experience those additional features (except the additional languages) are not making the difference.
In order to compare the time it takes to do the actual recognition with both MLKit and Apple Vision I created a little test set with different images. (You can access the test project on GitHub) The test set contains rotated text in images, images with low and high resolution and images with different fonts:

When I tested with an iPhone 12 the elapsed times for the recognition results were quite surprising. MLKit beats Apple Vision easily:
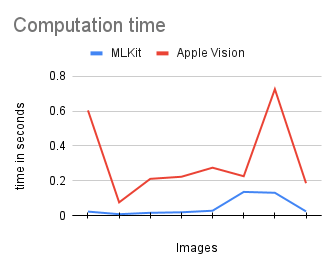
After some test runs with multiple iterations the average time for MLKit was ~ 0.05 seconds and for Apple Vision ~ 0.31 seconds. That is a factor 6 which is pretty significant. The peaks are caused by high resolution images. In a real world project it might be a good idea to downsample high resolution images to improve recognition times. But even with low resolution images MLKit clearly outperformed Apple Vision. Feel free to test it by yourself with my demo application, which also includes all tests in this blog post.
When part of your project is continuously performing OCR on the camera output, you will benefit from MLKit’s much faster recognition.
The next test set I created contains the same image with different resolutions. The set contains 15 images with a resolution from 500×500 pixels (top-left) to 50×50 pixels (bottom-right):

The resulting graph of the different recognitions:
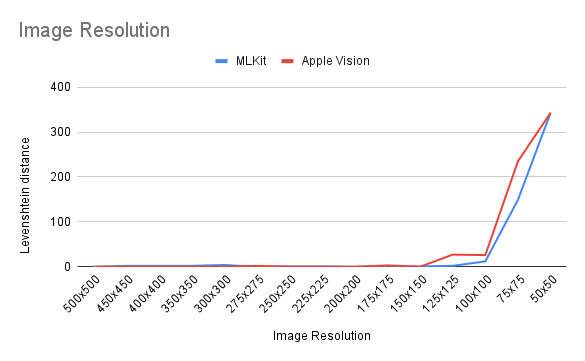
On the y-axis I used the Levenshtein distance in order to measure the difference between the expected and the recognized text. The lower the value the fewer differences between strings, the better the result. As you can see both competitors perform pretty similarly with this test set. MLKit delivers better results with the 125×125 image. The results with the 100×100 image are still usable with both frameworks, which is pretty impressive. The 100×100 image looks like this:
![]()
Another thing we can see in this graph ist, that the recognition in both frameworks does not benefit from higher resolutions after a certain point. Hence downsampling is often useful to reduce computation times.
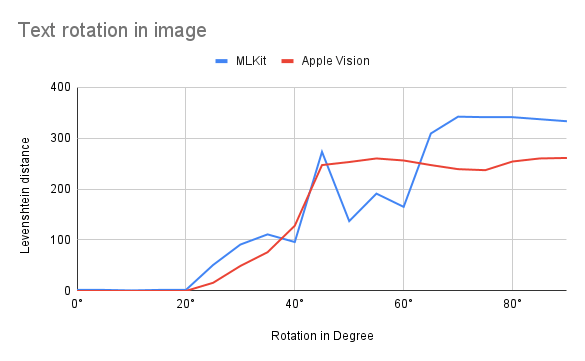
The last thing I compared was how the rotation of the text has an effect on the recognition. The test set contains images from 0° to 90° with 5° steps resulting in 19 testimages (including the 0°). The images contain the same text simply rotated by the amount of degrees:

The resulting graph shows that the results of both frameworks do not get worse until 20° are reached. After that Apple Vision performs slightly better. But like I mentioned earlier other test sets might bring different results. Test it with images similar to your use cases.
Both Google and Apple offer great frameworks for On-device OCR for free. With my test sets Apple Vision framework performed slightly better with rotated text in images. On the other hand, MLKit’s results were slightly better with text in low resolution images. One significant difference is the computation time for the recognition. With my test set computations times from MLKit were 6 times faster than Apple Vision’s. If computation time does not matter for you, check out if your use cases benefit from Apple Vision’s language correction phase and feel free to add test sets to my test project.

21. Juni 2021
11 Minuten zum lesen
11 Min.
21. Juni 2021
8 Minuten zum lesen
8 Min.